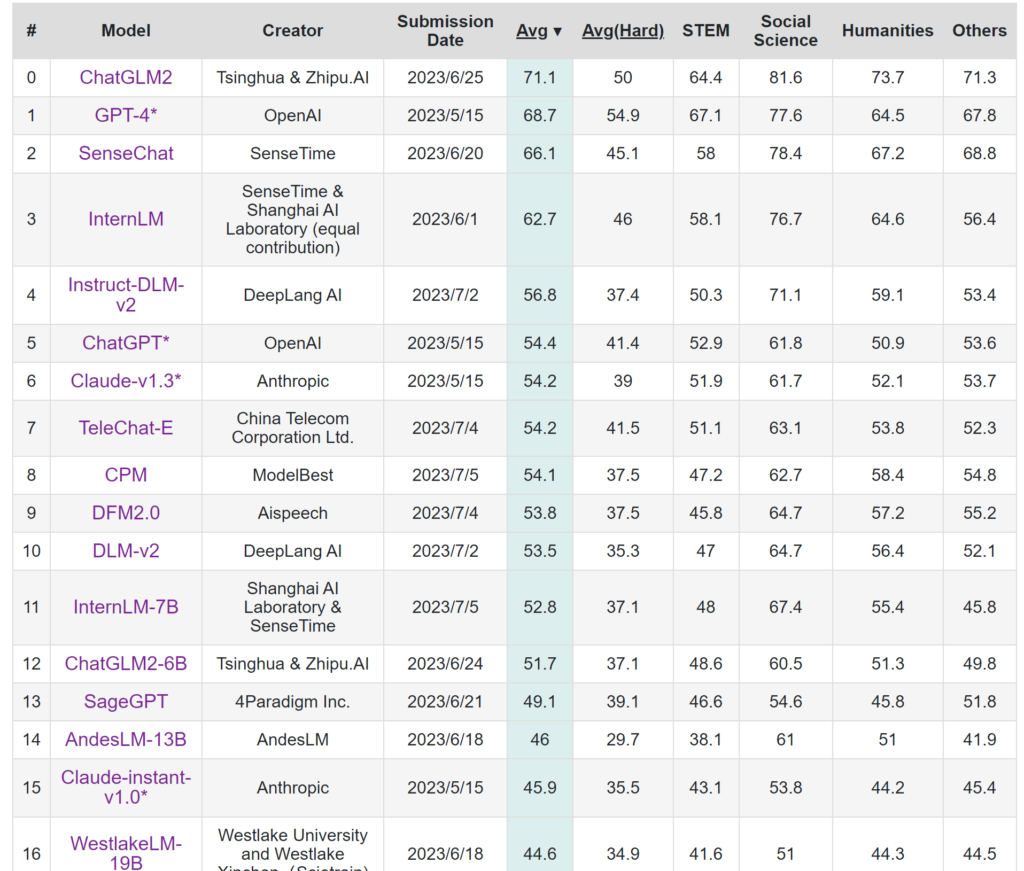
在2023/06/24 Tsinghua & Zhipu.AI发布了ChatGLM-6B开源模型,在C-Eval榜单中,它取得了中文开源模型的佳绩!
介绍
ChatGLM2-6B项目/模型地址(国内):https://modelscope.cn/models/ZhipuAI/chatglm2-6b/summary
ChatGLM2-6B项目地址(Github):https://github.com/THUDM/ChatGLM2-6B
ChatGLM2-6B模型文件:https://huggingface.co/THUDM/chatglm2-6b
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。

它具备很好的中文沟通能力
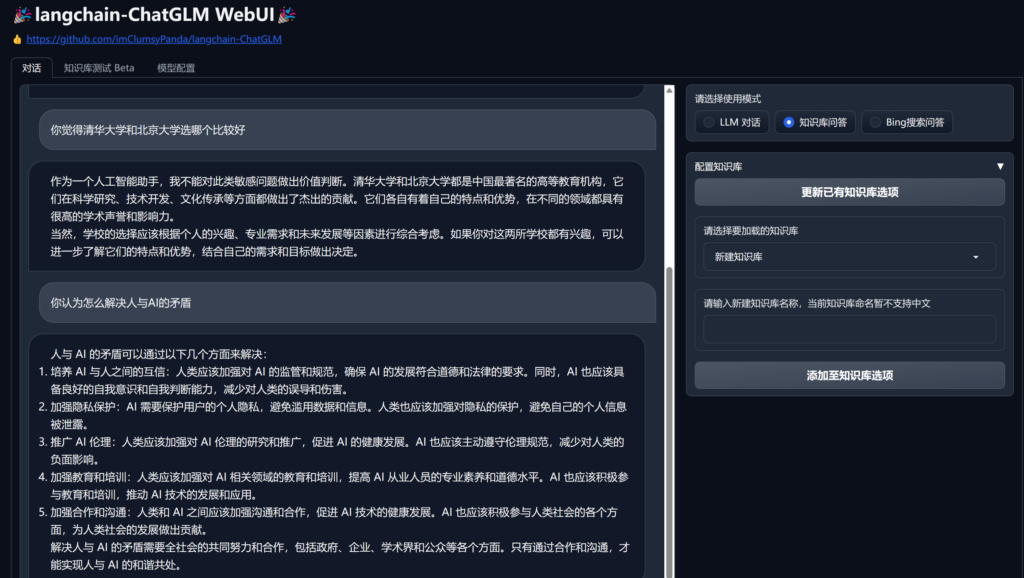
接下来,让我们看看如何安装Langchain-ChatGLM2-6B
安装ChatGLM2-6B或Langchain-ChatGLM2-6B
要求与准备
我们需要用到阿里云的机器学习平台 PAI-交互式建模 PAI-DSW,个人开发者可以领取阿里云免费提供的资源包,凭借这点来说,阿里云做得很好!
阿里云试用中心(PAI-DSW):https://free.aliyun.com/?product=9602825&crowd=personal
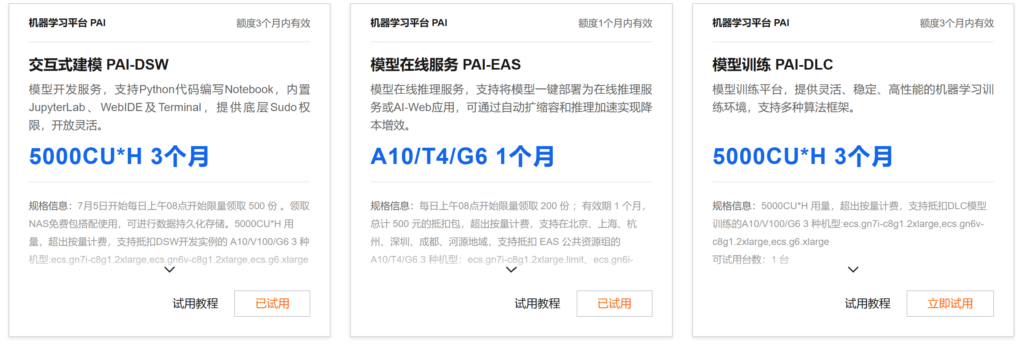
给的资源包足够我们测试了,我们领取PAI-DSW体验资源包后,去工作台开通PAI工作空间,本教程的演示地域是杭州,当然,你也可以按照你的规划来选择地域。它给的额度虽然多,但到后期也要注意别用超了
新建PAI-DSW实例
然后我们进入DSW,新建实例
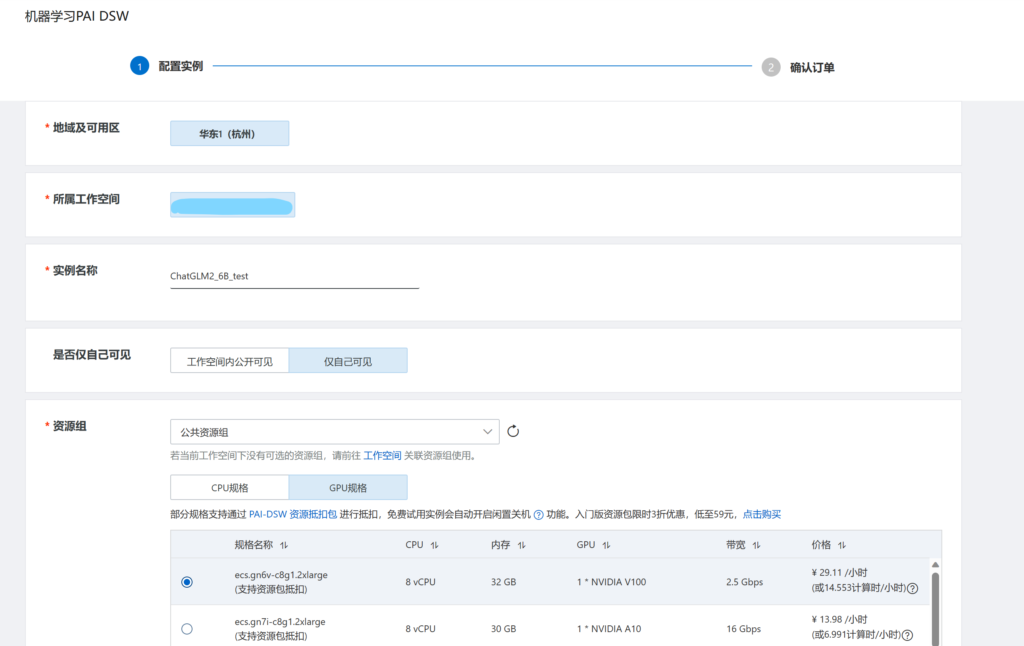
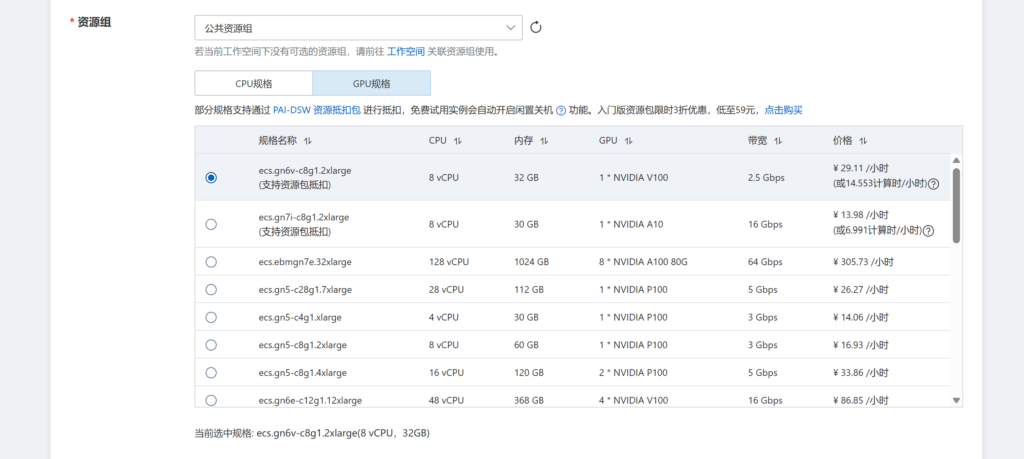
我们选择ecs.gn6v-c8g1.2xlarge,在体验资源包中性能最佳
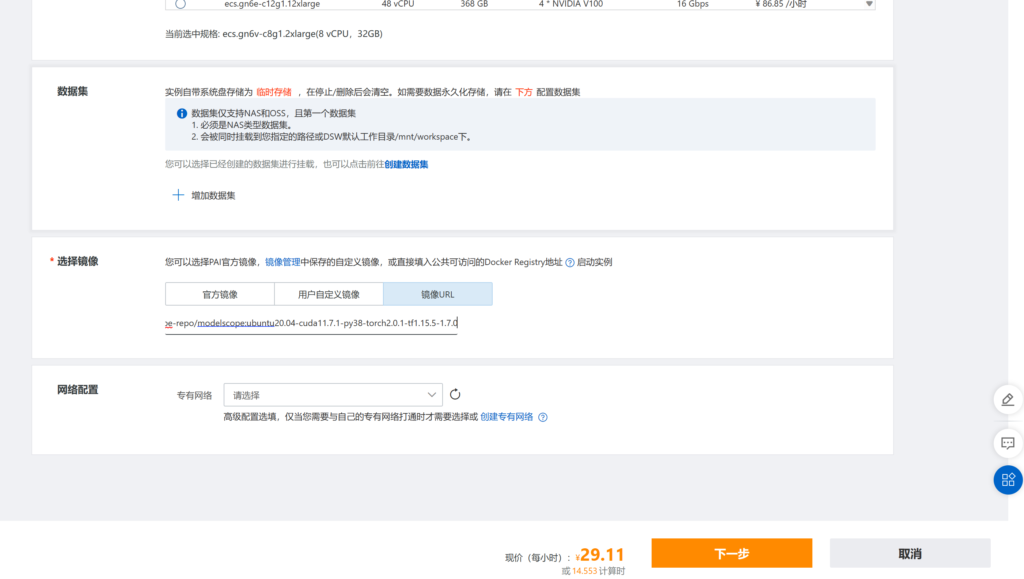
我们选择镜像URL
杭州:registry-vpc.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.7.0
或者
全地域:(官方镜像)pytorch:1.12-gpu-py39-cu113-ubuntu20.04
使用PAI-DSW实例
我们将Langchain-ChatGLM2-6B-Aliyun-PAI-DSW.ipynb文件拖入Notebook
文章的末尾有下载地址
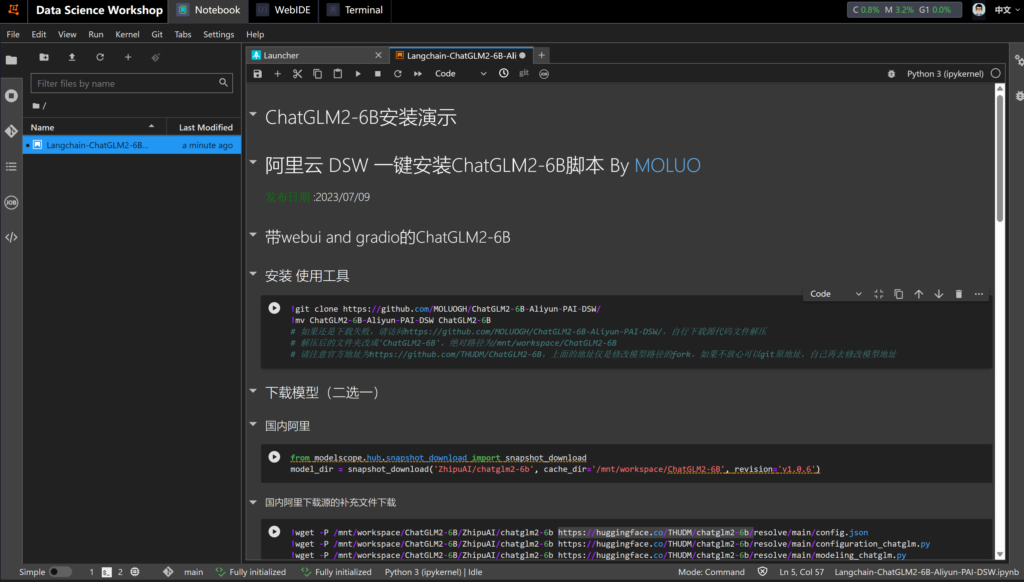
接下来会有三种安装方式的介绍,请根据自己需要,跳转到文章的相应位置
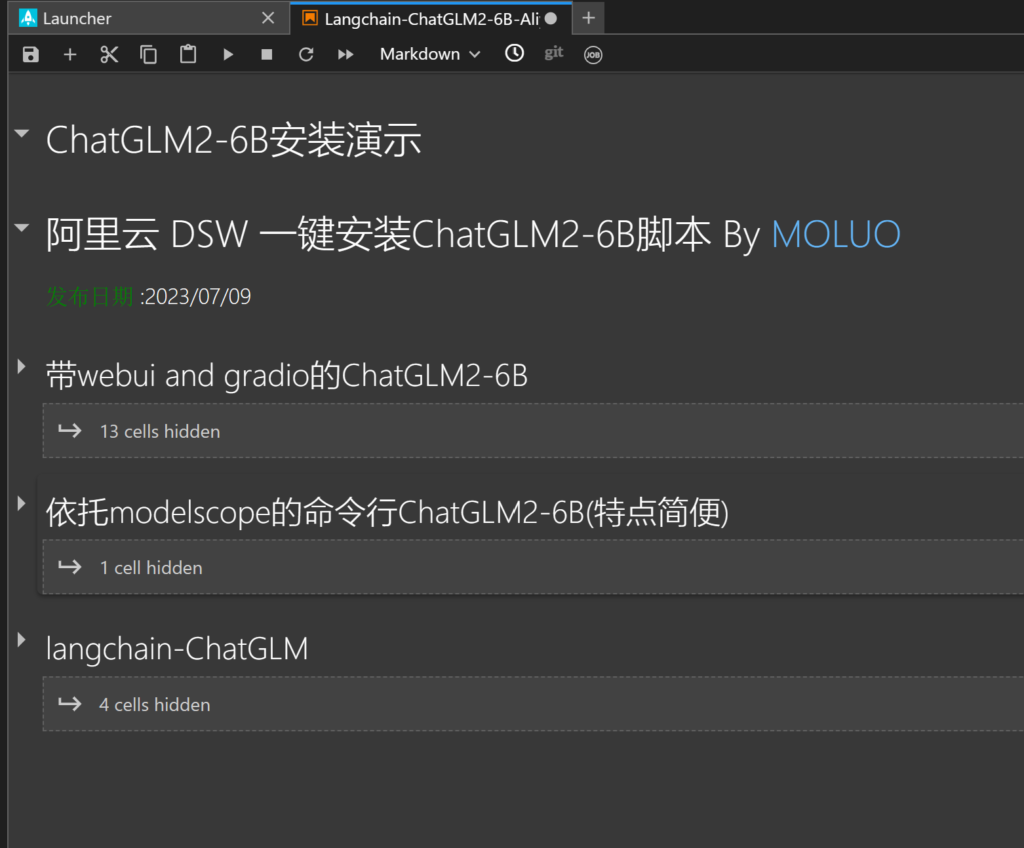
带webui and gradio的ChatGLM2-6B
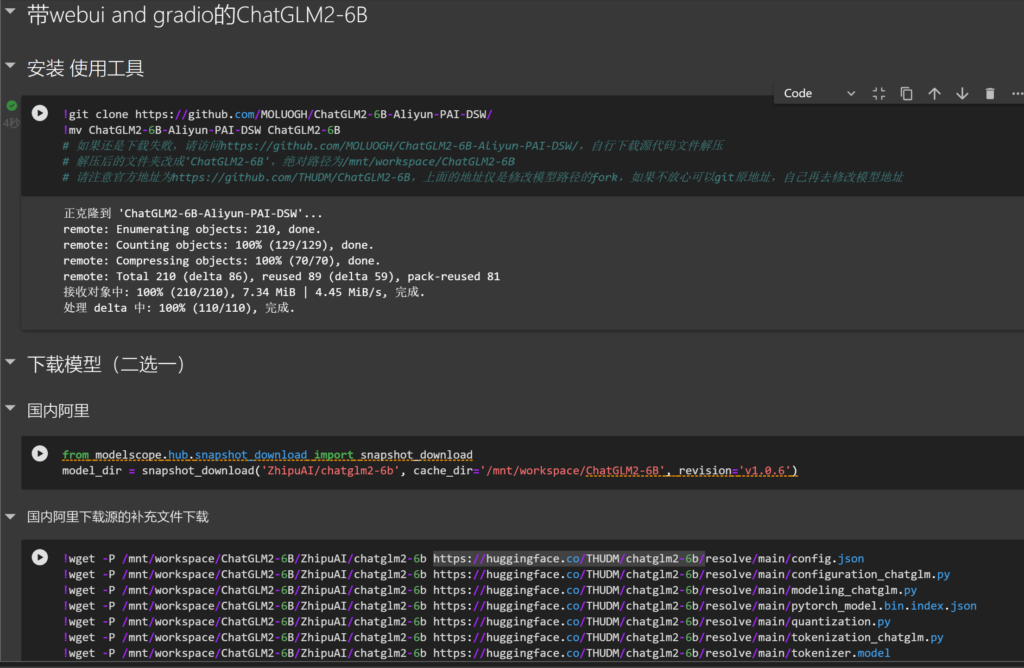
git clone项目
tips:
如果还是下载失败,请访问https://github.com/MOLUOGH/ChatGLM2-6B-Aliyun-PAI-DSW/,自行下载源代码文件解压
解压后的文件夹改成'ChatGLM2-6B',绝对路径为/mnt/workspace/ChatGLM2-6B
请注意官方地址为https://github.com/THUDM/ChatGLM2-6B,上面的地址仅是修改模型路径的fork,如果不放心可以git原地址,自己再去修改模型地址
下载模型(二选一)
我们这里只演示从阿里源下载模型
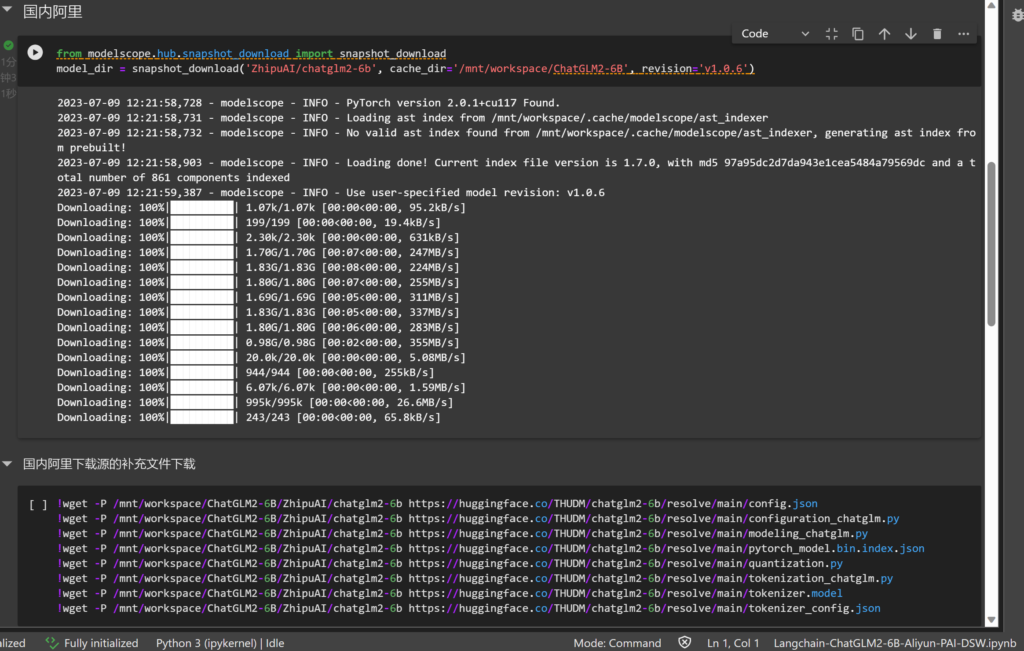
我们需要从 https://huggingface.co/THUDM/chatglm2-6b/ 获取一些文件
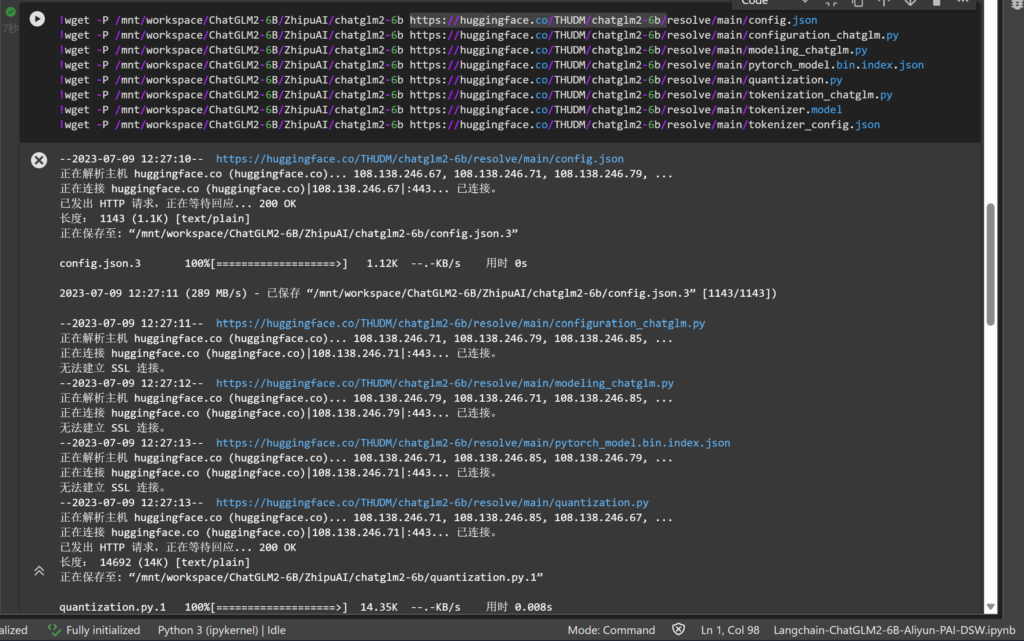
当然,你要多试几次,确保下载到,你也可以手动上传补齐文件
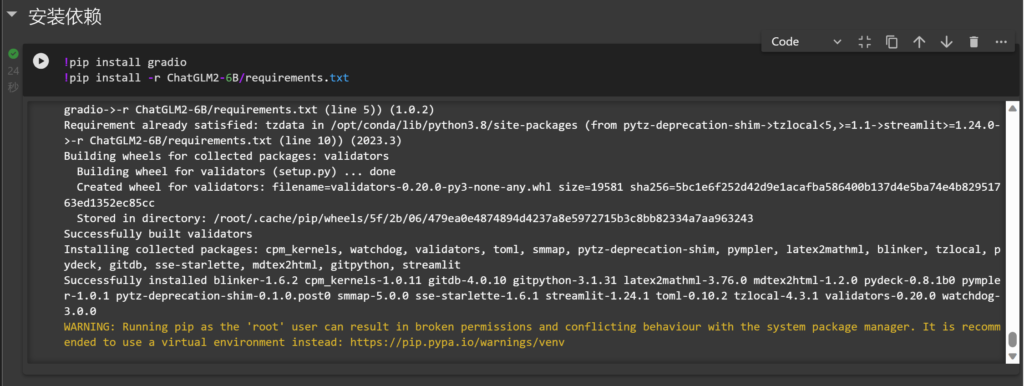
安装依赖
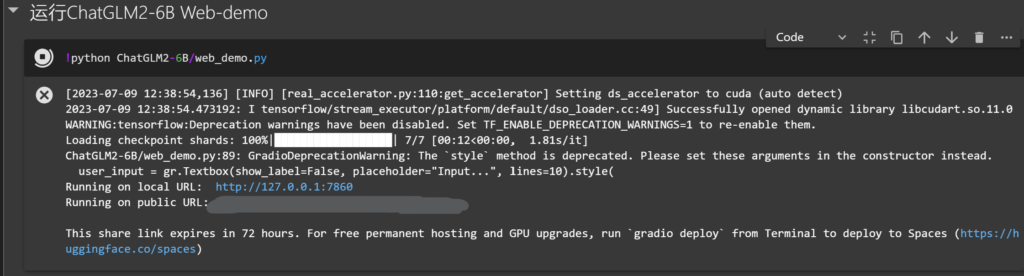
启动webui and gradio的ChatGLM2-6B
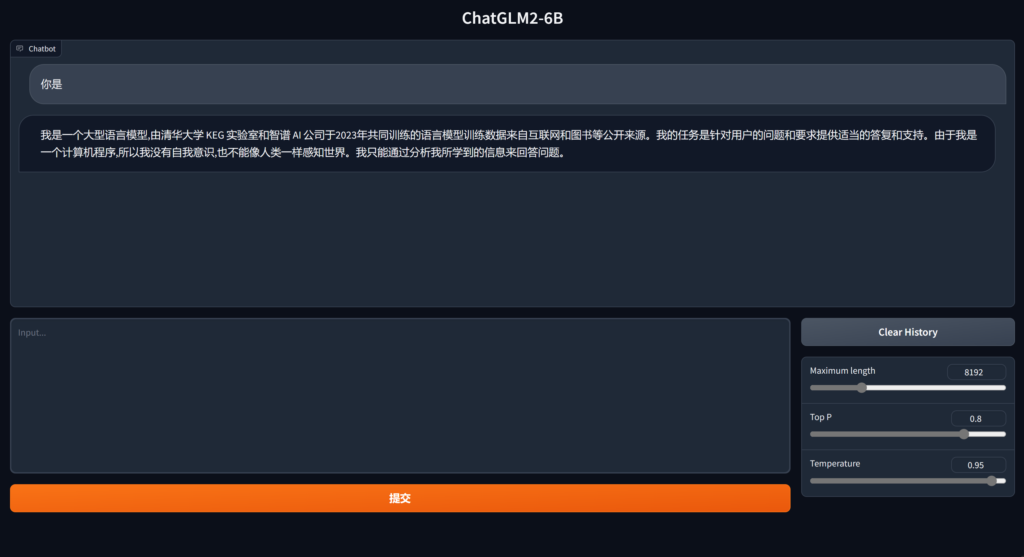
点击第一个链接就可以访问了
安装webui and gradio的ChatGLM2-6B的常见问题
- 默认开启share=True,可修改web-demo.py来关闭share功能
- 如果gradio启动失败,请根据提示解决,可以在Terminal重新安装gradio尝试
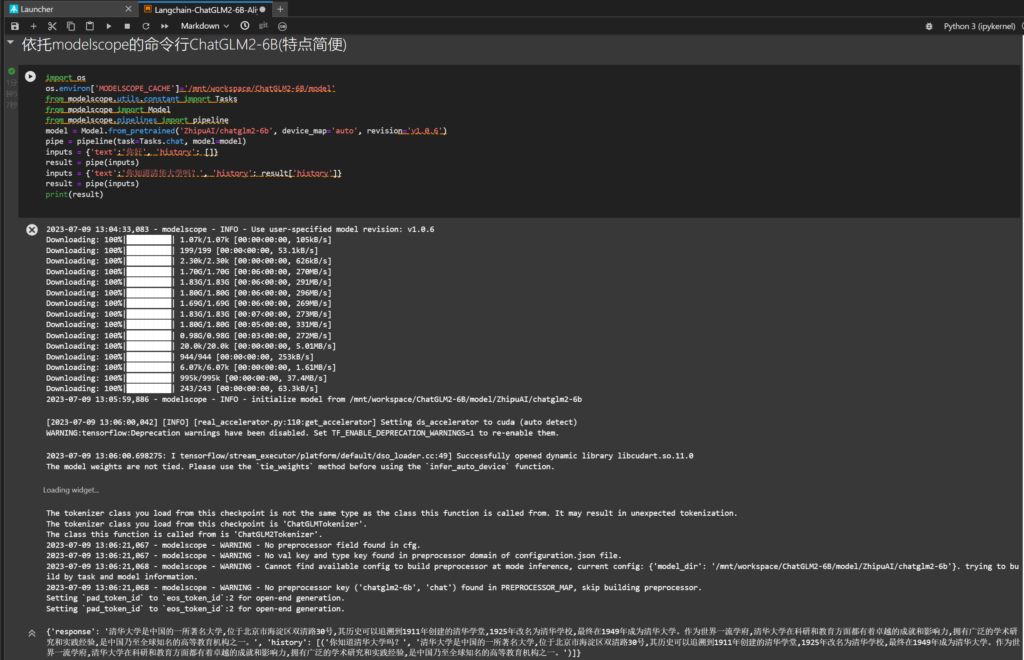
依托modelscope的命令行ChatGLM2-6B
这个安装方式的特点是十分简便
直接运行即可
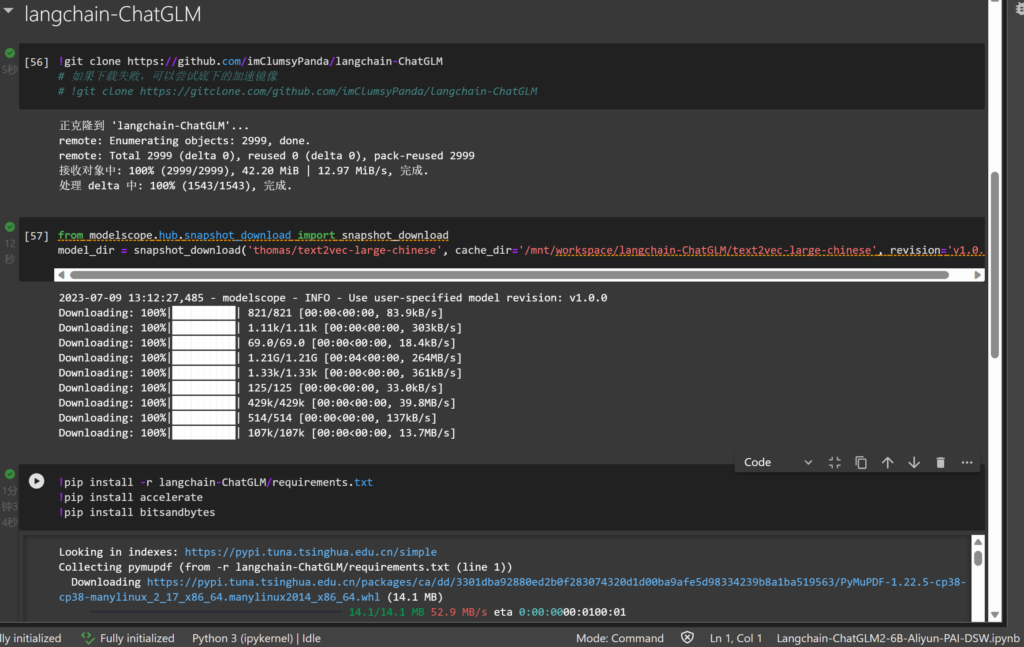
Langchain-ChatGLM
安装教程
运行前三行模块,分别git两个仓库并且安装依赖
接下来的教程需要一些linux基础知识
下载ChatGLM2-6B模型
参考安装ChatGLM2-6B时的模型下载https://www.mlvlog.com/1780.html#下载模型(二选一)
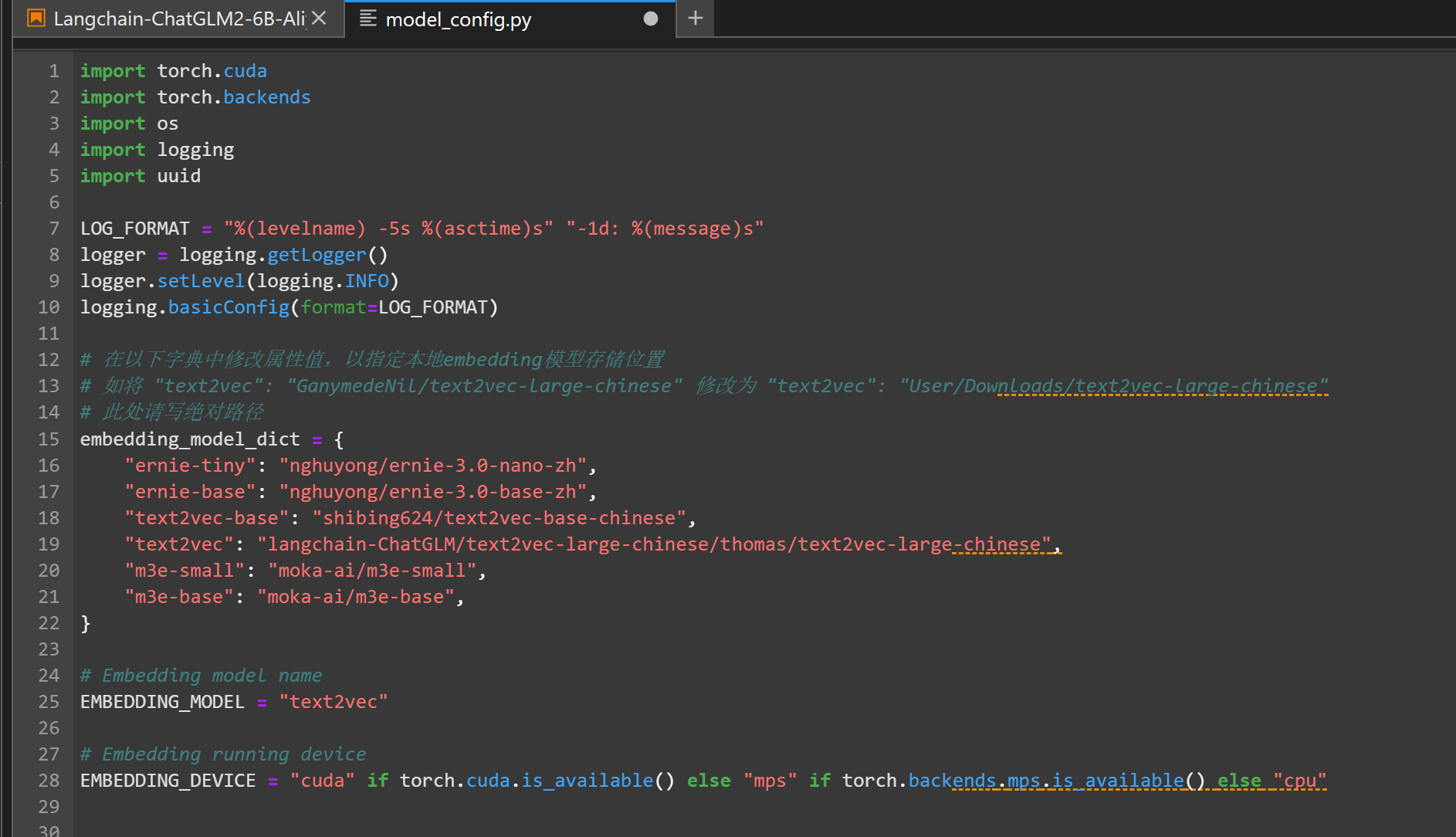
修改config
修改/langchain-ChatGLM/configs/model_config.py
- text2vec路径修改为langchain-ChatGLM/text2vec-large-chinese/thomas/text2vec-large-chinese
- chatglm2-6b路径修改为/mnt/workspace/ChatGLM2-6B/ZhipuAI/chatglm2-6b
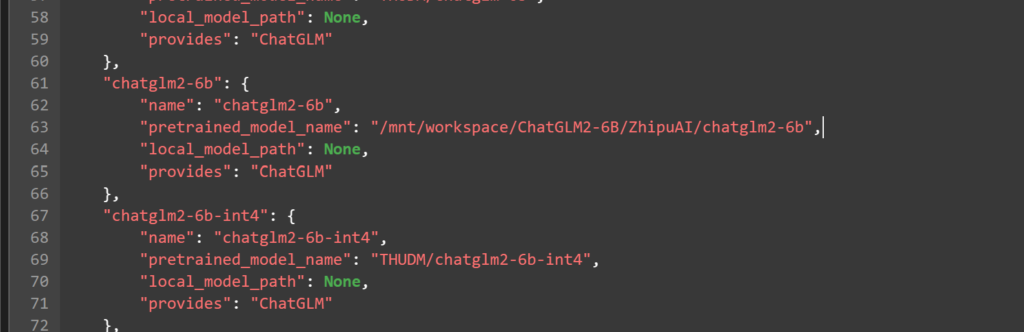
- 修改LLM 名称

也可以直接复制底下的代码到model_config.py
import torch.cuda
import torch.backends
import os
import logging
import uuid
LOG_FORMAT = "%(levelname) -5s %(asctime)s" "-1d: %(message)s"
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logging.basicConfig(format=LOG_FORMAT)
# 在以下字典中修改属性值,以指定本地embedding模型存储位置
# 如将 "text2vec": "GanymedeNil/text2vec-large-chinese" 修改为 "text2vec": "User/Downloads/text2vec-large-chinese"
# 此处请写绝对路径
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "langchain-ChatGLM/text2vec-large-chinese/thomas/text2vec-large-chinese",
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}
# Embedding model name
EMBEDDING_MODEL = "text2vec"
# Embedding running device
EMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
# supported LLM models
# llm_model_dict 处理了loader的一些预设行为,如加载位置,模型名称,模型处理器实例
# 在以下字典中修改属性值,以指定本地 LLM 模型存储位置
# 如将 "chatglm-6b" 的 "local_model_path" 由 None 修改为 "User/Downloads/chatglm-6b"
# 此处请写绝对路径
llm_model_dict = {
"chatglm-6b-int4-qe": {
"name": "chatglm-6b-int4-qe",
"pretrained_model_name": "THUDM/chatglm-6b-int4-qe",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b-int4": {
"name": "chatglm-6b-int4",
"pretrained_model_name": "THUDM/chatglm-6b-int4",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b-int8": {
"name": "chatglm-6b-int8",
"pretrained_model_name": "THUDM/chatglm-6b-int8",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm-6b": {
"name": "chatglm-6b",
"pretrained_model_name": "THUDM/chatglm-6b",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm2-6b": {
"name": "chatglm2-6b",
"pretrained_model_name": "/mnt/workspace/ChatGLM2-6B/ZhipuAI/chatglm2-6b",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm2-6b-int4": {
"name": "chatglm2-6b-int4",
"pretrained_model_name": "THUDM/chatglm2-6b-int4",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatglm2-6b-int8": {
"name": "chatglm2-6b-int8",
"pretrained_model_name": "THUDM/chatglm2-6b-int8",
"local_model_path": None,
"provides": "ChatGLM"
},
"chatyuan": {
"name": "chatyuan",
"pretrained_model_name": "ClueAI/ChatYuan-large-v2",
"local_model_path": None,
"provides": None
},
"moss": {
"name": "moss",
"pretrained_model_name": "fnlp/moss-moon-003-sft",
"local_model_path": None,
"provides": "MOSSLLM"
},
"vicuna-13b-hf": {
"name": "vicuna-13b-hf",
"pretrained_model_name": "vicuna-13b-hf",
"local_model_path": None,
"provides": "LLamaLLM"
},
# 通过 fastchat 调用的模型请参考如下格式
"fastchat-chatglm-6b": {
"name": "chatglm-6b", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "chatglm-6b",
"local_model_path": None,
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
"fastchat-chatglm2-6b": {
"name": "chatglm2-6b", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "chatglm2-6b",
"local_model_path": None,
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
# 通过 fastchat 调用的模型请参考如下格式
"fastchat-vicuna-13b-hf": {
"name": "vicuna-13b-hf", # "name"修改为fastchat服务中的"model_name"
"pretrained_model_name": "vicuna-13b-hf",
"local_model_path": None,
"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM"
"api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"
},
}
# LLM 名称
LLM_MODEL = "chatglm2-6b"
# 量化加载8bit 模型
LOAD_IN_8BIT = False
# Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.
BF16 = False
# 本地lora存放的位置
LORA_DIR = "loras/"
# LLM lora path,默认为空,如果有请直接指定文件夹路径
LLM_LORA_PATH = ""
USE_LORA = True if LLM_LORA_PATH else False
# LLM streaming reponse
STREAMING = True
# Use p-tuning-v2 PrefixEncoder
USE_PTUNING_V2 = False
# LLM running device
LLM_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
# 知识库默认存储路径
KB_ROOT_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base")
# 基于上下文的prompt模版,请务必保留"{question}"和"{context}"
PROMPT_TEMPLATE = """已知信息:
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}"""
# 缓存知识库数量,如果是ChatGLM2,ChatGLM2-int4,ChatGLM2-int8模型若检索效果不好可以调成’10’
CACHED_VS_NUM = 1
# 文本分句长度
SENTENCE_SIZE = 100
# 匹配后单段上下文长度
CHUNK_SIZE = 250
# 传入LLM的历史记录长度
LLM_HISTORY_LEN = 3
# 知识库检索时返回的匹配内容条数
VECTOR_SEARCH_TOP_K = 5
# 知识检索内容相关度 Score, 数值范围约为0-1100,如果为0,则不生效,经测试设置为小于500时,匹配结果更精准
VECTOR_SEARCH_SCORE_THRESHOLD = 0
NLTK_DATA_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "nltk_data")
FLAG_USER_NAME = uuid.uuid4().hex
logger.info(f"""
loading model config
llm device: {LLM_DEVICE}
embedding device: {EMBEDDING_DEVICE}
dir: {os.path.dirname(os.path.dirname(__file__))}
flagging username: {FLAG_USER_NAME}
""")
# 是否开启跨域,默认为False,如果需要开启,请设置为True
# is open cross domain
OPEN_CROSS_DOMAIN = False
# Bing 搜索必备变量
# 使用 Bing 搜索需要使用 Bing Subscription Key,需要在azure port中申请试用bing search
# 具体申请方式请见
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/create-bing-search-service-resource
# 使用python创建bing api 搜索实例详见:
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/quickstarts/rest/python
BING_SEARCH_URL = "https://api.bing.microsoft.com/v7.0/search"
# 注意不是bing Webmaster Tools的api key,
# 此外,如果是在服务器上,报Failed to establish a new connection: [Errno 110] Connection timed out
# 是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GG
BING_SUBSCRIPTION_KEY = ""
# 是否开启中文标题加强,以及标题增强的相关配置
# 通过增加标题判断,判断哪些文本为标题,并在metadata中进行标记;
# 然后将文本与往上一级的标题进行拼合,实现文本信息的增强。
ZH_TITLE_ENHANCE = False
启动
运行后我们发现报错(在pytorch:1.12-gpu-py39-cu113-ubuntu20.04中不会有此报错)
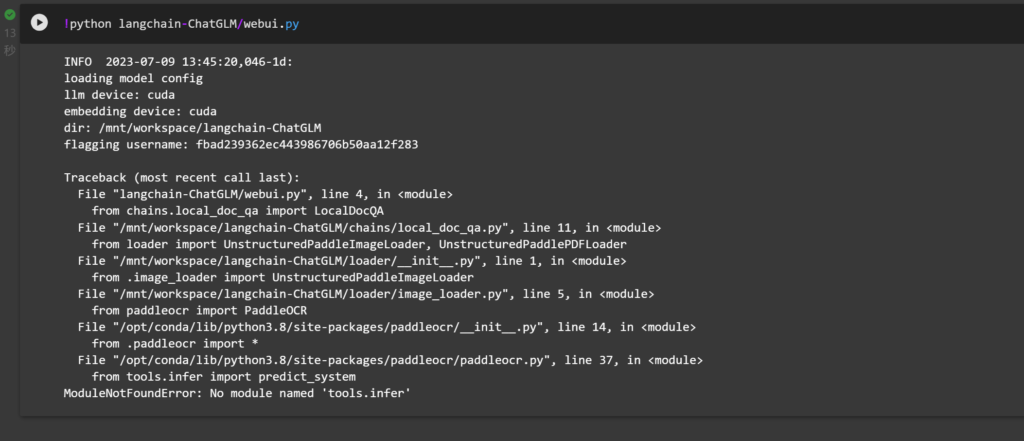
通过查询资料(https://blog.csdn.net/qq_42450100/article/details/125276839),得知
启动webui.py时ModuleNotFoundError: No module named 'tools.infer',这里是由于python本来有个tools,和paddleocr内部的tools冲突,解决方法:
- 找到paddleocr文件把所有导入tools.infer包的地方的前面加上paddleocr.即为paddleocr.tools.infer
- 把paddleocr/tools下面的infer文件夹移动到python本身的tools里面
我用的是方法二
在Terminal中运行
mv /opt/conda/lib/python3.8/site-packages/paddleocr/tools /opt/conda/lib/python3.8
然后再运行一次,成功加载
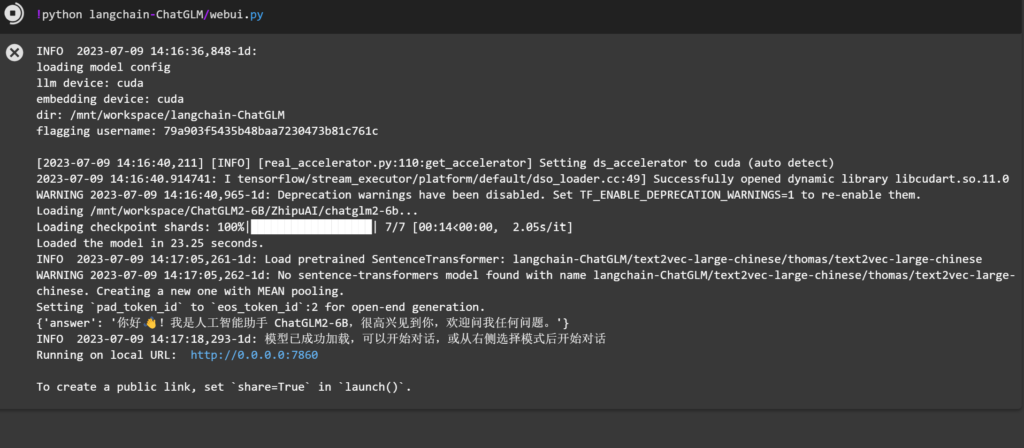
Langchain-ChatGLM安装常见问题
缺少文件的报错可能出现比较多,看好报错内容,补齐文件就行了。
结尾
我们希望能让更多人了解到ChatGLM2-6B,为此做了这一个脚本,如果要转载,请附上此文链接~
附
件
下
载
文件名称:Langchain-ChatGLM2-6B-Aliyun-PAI-DSW.ipynb
更新日期:2023-07-09
文件大小:10KB
提示:如遇问题或者链接失效请联系站长,欢迎捐赠本站以及广告合作!

Comments | NOTHING